Argus Catalog
An integrated AI·Data·API metadata platform that governs data, models, APIs, and AI agents in a single catalog. With strong support for air-gapped and on-premises environments, it secures enterprise-wide data sovereignty without ever sending data outside.
Concept Diagram
Highlights
Unified governance of data, models, APIs & AI
Brings the data catalog, ML model registry, API catalog, and AI Agent catalog together to deliver an enterprise-wide single source of truth (SSOT).
Auto-sync across 11 data sources
Automatically collects metadata from Hive, Impala, Kudu, Trino, StarRocks, Greenplum, Iceberg REST, PostgreSQL, MySQL, Oracle, and MSSQL, keeping schemas, statistics, and lineage up to date.
EnterpriseColumn-level cross-platform lineage
Automatically traces end-to-end lineage at the dataset and column level via SQL parsing, and generates ER diagrams from DDL parsing.
EnterpriseAir-gapped / on-prem + local LLMs
Integrates with OpenAI and Anthropic as well as local LLMs such as Ollama, enabling full AI governance even in closed networks where data never leaves.
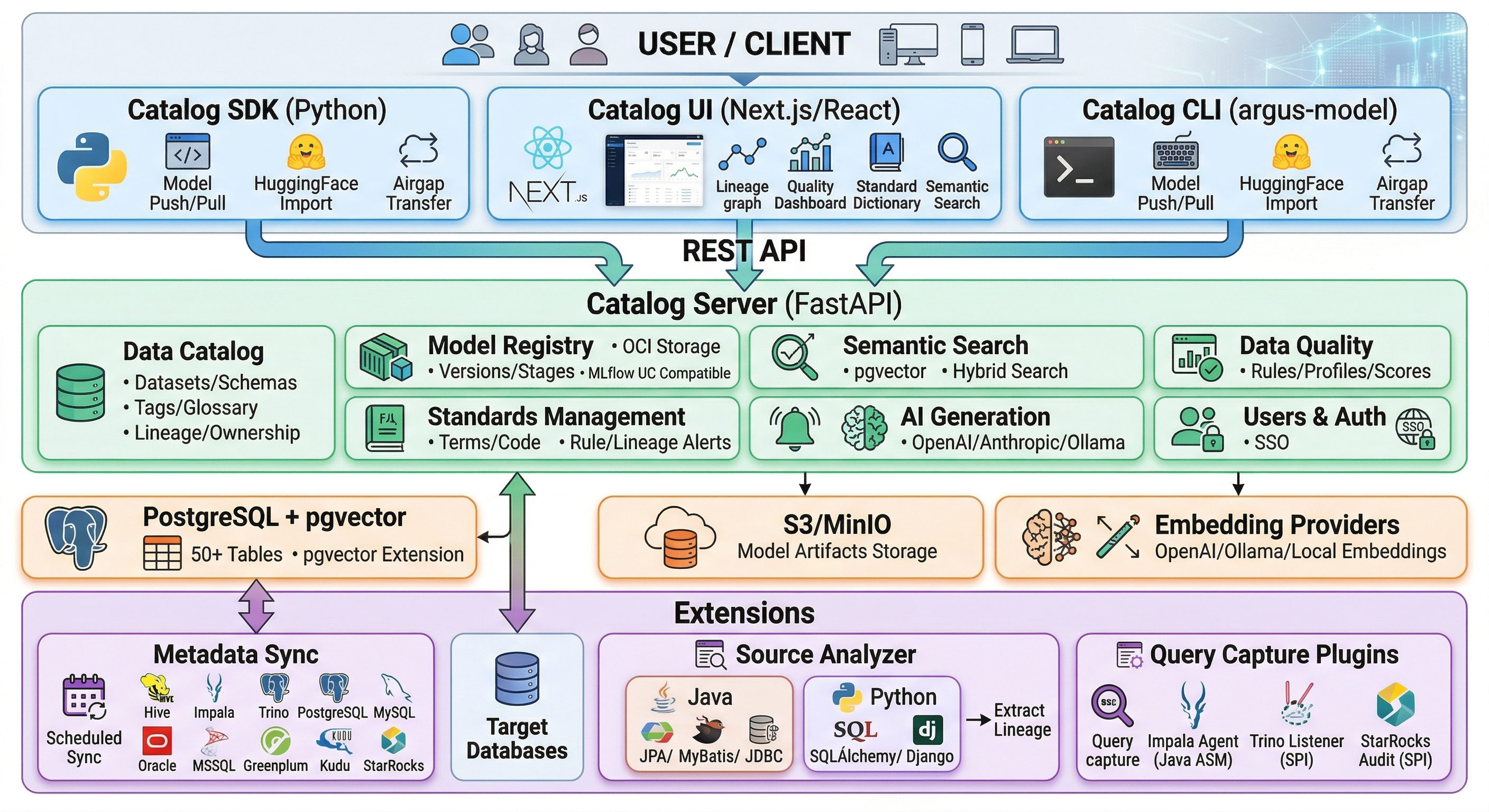
Platform Architecture
An end-to-end metadata platform where Catalog UI, Server, Extensions, and SDK work organically together.
Core Capabilities
From data catalog and search to quality & governance, ML model registry, and AI — the six pillars of enterprise metadata management in a single platform.
Data Catalog
The core for discovering, trusting, and governing datasets.
Search & Discovery
Find data fast with hybrid search that blends keywords and meaning.
Data Quality
Profiles source databases directly and validates with rules.
Metadata Governance
Catalogs not just data but APIs and AI agents too.
ML Model Registry
MLflow/OCI-compatible model governance with air-gapped import.
AI
Auto-generates metadata with LLMs and queries the catalog.
Catalog Federation
Federate multiple Argus instances into one for unified search and browse — with air-gap-friendly HARVEST mirroring and local promotion.
Query-based lineage & relationship collection
Automatically collects lineage and relationships from real queries on operational SQL engines.
Static source-code analysis
Extracts DB table mappings from application source code to enrich lineage.
Enterprise connector sync
Bulk-syncs metadata from a wide range of sources automatically.
LDAP/AD user sync
Auto-manages catalog users with the corporate directory as the source of truth.
Editions
Use the open-source core freely with Community, or step up to Enterprise when you need extension modules and dedicated technical support — available in two editions.
Community
Use the entire open-source core without restrictions and run it yourself.
Enterprise
Everything in Community, plus extension modules and SLA-backed dedicated technical support.
An open-source metadata platform
Argus Catalog is fully open-sourced on GitHub under the Apache License 2.0. Apart from the metadata ingestion connectors, the entire core engine — backend, frontend, SDK, AI agent, and quality batch — is public, so enterprises can verify the code directly, extend it to fit their environment, and operate it without any external data leakage.
- Apache 2.0 with no commercial-use restrictions
- Verify and extend the code yourself
- Self-host in air-gapped / on-premises